Module
2: Internet: Introduction, Objectives, network, TCP/IP, Client server model,
E-mail, finger and top, USENET, news groups, internet programming WWW, Hyper
Text, http, URL, HTML Programming.
Introduction
to Internet
Internet is
a global communication system that links together thousands of individual
networks. It allows exchange of information between two or more computers on a
network. Thus internet helps in transfer of messages through mail, chat, video
& audio conference, etc. It has become mandatory for day-to-day activities:
bills payment, online shopping and surfing, tutoring, working, communicating
with peers, etc.
Internet was
evolved in 1969, under the project called ARPANET (Advanced Research Projects
Agency Network) to connect computers at different universities and U.S.
defence. Soon after the people from different backgrounds such as engineers,
scientists, students and researchers started using the network for exchanging
information and messages.
In 1990s the
internetworking of ARPANET, NSFnet and other private networks resulted into
Internet. Therefore, Internet is a global network of computer networks’ . It
comprises of millions of computing devices that carry and transfer volumes of
information from one device to the other. Desktop computers, mainframes, GPS
units, cell phones, car alarms, video game consoles, are connected to the Net.
How Do I Connect to the
Internet?

· Connection - Phone
Line, Cable, DSL, Wireless, ...
· Modem
· Network Software -
TCP/IP
· Application Software
- Web Browser, Email, ...
· Internet Service
Provider (ISP)
What Can I Do on the Internet?
· Send and receive email messages.
· Download free
software with FTP (File Transfer Protocol).
· Post our opinion to a
Usenet newsgroup.
· Surf the World Wide
Web.
· And much, much more.
· There is no charge
for most services.
World Wide Web(WWW) The World Wide Web (WWW) or web is
an internet based service, which uses common set of rules known as protocols,
to distribute documents across the Internet in a standard way.
World Wide
Web, which is also known as a Web, is a collection of websites or web pages
stored in web servers and connected to local computers through the internet.
These websites contain text pages, digital images, audios, videos, etc. Users
can access the content of these sites from any part of the world over the
internet using their devices such as computers, laptops, cell phones, etc. The
WWW, along with internet, enables the retrieval and display of text and media
to your device.
The World
Wide Web. Or ‘Web’ is a part of the Internet. The Web is viewed through web
browser software such as Google chrome, Internet Explorer, Mozilla Firefox etc.
Using browsers one can access the digital libraries containing innumerable
articles, journals, e-books, news, tutorials stored in the form of web pages on
computers around the world called web servers-Today thousands of web
pages/websites are added to the WWW every hour.
· The Web was invented in 1991 by Tim Berners-Lee, while
consulting at CERN
· (European Organization for Nuclear Research) in
Switzerland. The Web is a distributed
information system.
· The Web contains
multimedia.
· Information in the
Web is connected by hyperlinks.
Difference between Internet and WWW:
The Internet is known as
“interconnection of computer networks”. The Internet is a massive network of
networks. It connects millions of computers together globally, forming a
network in which any computer can communicate with any other computer as long as
they are both connected to the Internet. Information that travels over the
Internet does so via a variety of languages known as protocols.
The World Wide Web, or “Web” for short, or simply Web, is a massive collection of digital pages to access information over the Internet. The Web uses the HTTP protocol, to transmit data and allows applications to communicate in order to exchange business logic. The Web also uses browsers, such as Internet Explorer or Firefox. to access web documents called Web pages that are linked to each other via hyperlinks. Web documents also contain graphics, sounds, text and video.


Objectives of Internet
Web chat web
chat is an application that allows you to send and receive messages u break
tune with others.
Network
What is
a Network?
A computer network is a group of interconnected nodes or
computing devices that exchange data and resources with each other. A network
connection between these devices can be established using cable or wireless
media. Once a connection is established, communication protocols --
such as TCP/IP, Simple Mail Transfer Protocol and Hypertext
Transfer Protocol -- are used to exchange data between the networked devices.
The first example of a computer network was the Advanced
Research Projects Agency Network. This packet-switched network was created in
the late 1960s by ARPA, a U.S. Department of Defense agency.
A computer network can be as small as two laptops
connected through an Ethernet cable or as complex as the internet,
which is a global system of computer networks.
TCP/IP
TCP/IP was designed and developed by the Department of
Defense (DoD) in the 1960s and is based on standard protocols. It stands for
Transmission Control Protocol/Internet Protocol. The TCP/IP model is
a concise version of the OSI model. It contains four layers, unlike the seven
layers in the OSI model.
What
Does TCP/IP Do?
The main work of TCP/IP is to transfer the data of a computer from
one device to another. The main condition of this process is to make data
reliable and accurate so that the receiver will receive the same information
which is sent by the sender. To ensure that, each message reaches its final
destination accurately, the TCP/IP model divides its data into packets and
combines them at the other end, which helps in maintaining the accuracy of the
data while transferring from one end to another end.
What is
the Difference between TCP and IP?
TCP and IP are different protocols of Computer
Networks. The basic difference between TCP (Transmission Control Protocol) and
IP (Internet Protocol) is in the transmission of data. In simple words, IP
finds the destination of the mail and TCP has the work to send and receive the
mail. UDP is another protocol, which does not require IP to communicate with
another computer. IP is required by only TCP. This is the basic difference
between TCP and IP.
How Does the TCP/IP Model Work?
Whenever we want to send something over the internet using the TCP/IP Model, the TCP/IP Model divides the data into packets at the sender’s end and the same packets have to be recombined at the receiver’s end to form the same data, and this thing happens to maintain the accuracy of the data. TCP/IP model divides the data into a 4-layer procedure, where the data first go into this layer in one order and again in reverse order to get organized in the same way at the receiver’s end.

For more, you can refer to TCP/IP in Computer Networking.
Layers of TCP/IP Model
Application Layer
Transport Layer(TCP/UDP)
Network/Internet Layer(IP)
Data Link Layer (MAC)
Physical Layer
The diagrammatic comparison of the TCP/IP and OSI model
is as follows:
1. Physical Layer
It is a group of applications requiring network communications.
This layer is responsible for generating the data and requesting connections.
It acts on behalf of the sender and the Network Access layer on the behalf of
the receiver. During this article, we will be talking on the behalf of the
receiver.
2. Data
Link Layer
The packet’s network protocol type, in this case, TCP/IP, is
identified by the data-link layer. Error prevention and “framing” are also
provided by the data-link layer. Point-to-Point Protocol
(PPP) framing and Ethernet IEEE 802.2 framing are two examples of
data-link layer protocols.
3.
Internet Layer
This layer parallels the functions of OSI’s Network layer. It
defines the protocols which are responsible for the logical transmission of
data over the entire network. The main protocols residing at this layer are as
follows:
IP: IP stands
for Internet Protocol and it is responsible for delivering packets from the
source host to the destination host by looking at the IP addresses in the
packet headers. IP has 2 versions: IPv4 and IPv6. IPv4 is the one that most
websites are using currently. But IPv6 is growing as the number of IPv4 addresses
is limited in number when compared to the number of users.
ICMP: ICMP stands
for Internet Control Message Protocol. It is encapsulated within IP datagrams
and is responsible for providing hosts with information about network problems.
ARP: ARP stands for Address Resolution Protocol. Its job
is to find the hardware address of a host from a known IP address. ARP has
several types: Reverse ARP, Proxy ARP, Gratuitous ARP, and Inverse ARP.
The Internet Layer is a layer in the Internet Protocol (IP) suite,
which is the set of protocols that define the Internet. The Internet Layer is
responsible for routing packets of data from one device to another across a
network. It does this by assigning each device a unique IP address, which is
used to identify the device and determine the route that packets should take to
reach it.
Example: Imagine
that you are using a computer to send an email to a friend. When you click
“send,” the email is broken down into smaller packets of data, which are then
sent to the Internet Layer for routing. The Internet Layer assigns an IP
address to each packet and uses routing tables to determine the best route for
the packet to take to reach its destination. The packet is then forwarded to
the next hop on its route until it reaches its destination. When all of the
packets have been delivered, your friend’s computer can reassemble them into
the original email message.
In this example, the Internet Layer plays a crucial role in
delivering the email from your computer to your friend’s computer. It uses IP
addresses and routing tables to determine the best route for the packets to
take, and it ensures that the packets are delivered to the correct destination.
Without the Internet Layer, it would not be possible to send data across the
Internet.
4.
Transport Layer
The TCP/IP transport layer protocols exchange data receipt
acknowledgments and retransmit missing packets to ensure that packets arrive in
order and without error. End-to-end communication is referred to as such.
Transmission Control Protocol (TCP) and User Datagram Protocol are transport
layer protocols at this level (UDP).
TCP: Applications
can interact with one another using TCP as though they were
physically connected by a circuit. TCP transmits data in a way that resembles
character-by-character transmission rather than separate packets. A starting
point that establishes the connection, the whole transmission in byte order,
and an ending point that closes the connection make up this transmission.
UDP: The
datagram delivery service is provided by UDP, the other transport layer
protocol. Connections between receiving and sending hosts are not verified by
UDP. Applications that transport little amounts of data use UDP rather than TCP
because it eliminates the processes of establishing and validating connections.
5.
Application Layer
This layer is analogous to the transport layer of the OSI model.
It is responsible for end-to-end communication and error-free delivery of data.
It shields the upper-layer applications from the complexities of data. The
three main protocols present in this layer are:
HTTP
and HTTPS: HTTP stands for Hypertext transfer
protocol. It is used by the World Wide Web to manage communications between web
browsers and servers. HTTPS stands for HTTP-Secure. It is a combination of HTTP
with SSL(Secure Socket Layer). It is efficient in cases where the browser needs
to fill out forms, sign in, authenticate, and carry out bank transactions.
SSH: SSH stands
for Secure Shell. It is a terminal emulations software similar to Telnet. The
reason SSH is preferred is because of its ability to maintain the encrypted
connection. It sets up a secure session over a TCP/IP connection.
NTP: NTP stands
for Network Time Protocol. It is used to synchronize the clocks on our computer
to one standard time source. It is very useful in situations like bank
transactions. Assume the following situation without the presence of NTP.
Suppose you carry out a transaction, where your computer reads the time at 2:30
PM while the server records it at 2:28 PM. The server can crash very badly if
it’s out of sync.
The
host-to-host layer is a layer in the OSI (Open Systems
Interconnection) model that is responsible for providing communication between
hosts (computers or other devices) on a network. It is also known as the
transport layer.
Some common use cases for the host-to-host layer include:
Reliable
Data Transfer: The host-to-host layer ensures
that data is transferred reliably between hosts by using techniques like error
correction and flow control. For example, if a packet of data is lost during
transmission, the host-to-host layer can request that the packet be
retransmitted to ensure that all data is received correctly.
Segmentation
and Reassembly: The host-to-host layer is
responsible for breaking up large blocks of data into smaller segments that can
be transmitted over the network, and then reassembling the data at the
destination. This allows data to be transmitted more efficiently and helps to
avoid overloading the network.
Multiplexing
and Demultiplexing: The host-to-host layer is
responsible for multiplexing data from multiple sources onto a single network
connection, and then demultiplexing the data at the destination. This allows
multiple devices to share the same network connection and helps to improve the
utilization of the network.
End-to-End
Communication: The host-to-host layer provides
a connection-oriented service that allows hosts to communicate with each other
end-to-end, without the need for intermediate devices to be involved in the
communication.
Example: Consider
a network with two hosts, A and B. Host A wants to send a file to host B. The
host-to-host layer in host A will break the file into smaller segments, add
error correction and flow control information, and then transmit the segments
over the network to host B. The host-to-host layer in host B will receive the
segments, check for errors, and reassemble the file. Once the file has been
transferred successfully, the host-to-host layer in host B will acknowledge
receipt of the file to host A.
In this example, the host-to-host layer is responsible for
providing a reliable connection between host A and host B, breaking the file
into smaller segments, and reassembling the segments at the destination. It is
also responsible for multiplexing and demultiplexing the data and providing
end-to-end communication between the two hosts.
Client and Server model
A client and server networking model is a model in which computers
such as servers provide the network services to the other computers such as
clients to perform a user based tasks. This model is known as client-server
networking model.
The application programs using the client-server model should
follow the given below strategies:

An application program is known as a client program, running on
the local machine that requests for a service from an application program known
as a server program, running on the remote machine.
A client program runs only when it requests for a service from the
server while the server program runs all time as it does not know when its
service is required.
A server provides a service for many clients not just for a single
client. Therefore, we can say that client-server follows the many-to-one
relationship. Many clients can use the service of one server.
Services are required frequently, and many users have a specific
client-server application program. For example, the client-server application
program allows the user to access the files, send e-mail, and so on. If the
services are more customized, then we should have one generic application
program that allows the user to access the services available on the remote
computer.
Client
A client is a program that runs on the local machine requesting
service from the server. A client program is a finite program means that the
service started by the user and terminates when the service is completed.
Server
A server is a program that runs on the remote machine providing
services to the clients. When the client requests for a service, then the
server opens the door for the incoming requests, but it never initiates the
service.
A server program is an infinite program means that when it starts,
it runs infinitely unless the problem arises. The server waits for the incoming
requests from the clients. When the request arrives at the server, then it
responds to the request.
Advantages
of Client-server networks:
Centralized: Centralized back-up is possible in client-server
networks, i.e., all the data is stored in a server.
Security: These
networks are more secure as all the shared resources are centrally
administered.
Performance: The
use of the dedicated server increases the speed of sharing resources. This
increases the performance of the overall system.
Scalability: We can increase the number of clients and
servers separately, i.e., the new element can be added, or we can add a new
node in a network at any time.
What is email
Email is electronic mail, the most reliable and legal mode of
communication that uses electronic devices and data transmission to deliver
messages across different computer networks to one or a group of recipients in
the internet.
Email are universal as all the email servers need to be compliant
to the RFC rules that are predefined by the IETF (Internet Engineering
Task Force).
You can send individual emails or send to a group of people using
different email services in a single go.
Emails can be sent to notify people or remind people.
Emails are async mode of communication and the recipients can
respond later at their convenience.
Cc/ Bcc options in email are useful to keep people in loop, even
when the actual recipients are different set of people.
With anytime, anywhere options and universal applications, emails
are still the most trusted mode of communication for intra-organization
communication.
Emails are most effective mode of communication, in terms of cost,
speed and reliability.
When you send an email to your friends or contacts, it is almost immediately delivered to the recipients within the blink of an eye. However there is a set of processes that happens in the background from when you send the email, and till the email is delivered to the recipient's Inbox.
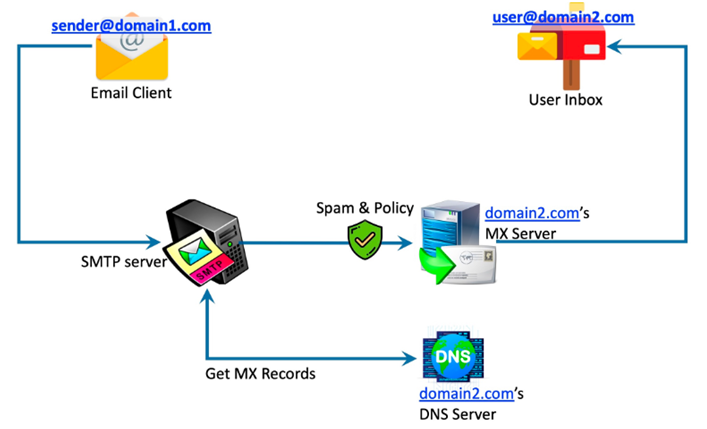
A brief outline of
the process is explained below:
You login to your email (webmail or mobile device or desktop
client).
Open the composer and specify the subject, type in the email
content, choose the recipients and draft the email.
You hit send and send the email. Now the backend process
begins.
The email client (web/ mobile/ desktop) connects to
the Outgoing SMTP server based on the email account you used.
The Emil client handovers the email in MIME
format to the Outgoing SMTP server.
The Outgoing SMTP validates the sender details and
processes the message for sending.
It also verifies the attachment size and verifies whether the
email complies with the outgoing email policy set for the particular
account.
Once the entire validation is completed, it places it
in Outgoing queue.
The SMTP server looks up the DNS records of
the domain and retrieves the MX records information of the
recipient servers (A Records in case no MX record is
found).
Then the SMTP Server connects with
the Recipient email server MTA and sends the email through
SMTP protocol.
The Recipient server now runs various checks -
including Spam and Virus checks for the email and accepts
the email based on
its Anti-spam and Anti-virus policies.
Then the Recipient server validates the recipient
account and delivers the email to the user's mail account, based on the
incoming email policies set for the account.
The user views the received email using his email client.
How Email Works
Email Bounces/ Undeliverable Messages
(554.x.x errors/ 5xx errors):
Once an email is sent from the client, the emails can be bounced
back as undeliverable emails due to any of the reasons below. These errors are
permanent errors and hence the emails will not be retried by the SMTP Servers.
Invalid
Domain:
When you send an email to an invalid domain, the SMTP server is
unable to lookup DNS information for the particular domain. In this case, the
email is bounced as undeliverable by the SMTP server itself.
Example:
You send an email to abc@yordomain.com instead of abc@yourdomain.com. In this
case, when there is no valid domain yordomain.com, the DNS
Lookup fails and the domain is considered invalid domain.
Solution: Check
the correct spelling of the domain name you have entered.
No MX Records found:
When you send an email to a valid domain, but there are no MX
records/ valid A Records for the domain (nothing is returned by the DNS
Servers), the email is bounced as undeliverable by the SMTP server
itself.
Solution: Check
with the recipient or the recipient administrator if this is a known issue.
Check for an alternate email address and send email there in case of emergency.
This is purely the issue at the recipient domain and can be resolved by the
admin of the recipients.
Invalid Recipients/ User unknown
When you send an email, but type the email address incorrectly or
send an email to an employee, who has left the organization, you may get such
errors.
Example: You
send an email to abb@yourdomain.com instead
of abc@yourdomain.com. The email is delivered to the MX records of
the yourdomain.com. But there is no valid account
like abb@yourdomain.com in the server, the recipient server bounces
back the email as undeliverable.
Solution: In
some cases, checking the email address for typos might help.
Email
Policy Violation:
The recipient email server may have some restrictions
or email policies applicable for incoming emails. If the email you
send violates such policies, your email might be rejected by the recipient
server.
Example: You
send an email to abc@yourdomain.com with .mov attachment file. If the
recipient server has an email policy to not accept .mov files, the recipient
server may reject the email based on the policy.
Other
reasons:
Other than the above common reasons, the recipient email servers
may reject or bounce the emails due to various reasons and errors. Most of the
times, the bounce email will include the reason the email was rejected.
Temporary Email Failures/ Retry Errors (451.x.x errors/ 4xx errors):
Sometimes when an SMTP Server connects with the recipient email
server, the recipient server returns temporary errors. In this case, the email
will be placed in Retry Queue, and the SMTP Server will try to deliver the
email to the recipient server in preset intervals. Mostly the emails
might be delivered on subsequent retried. If the email is not accepted by the
recipient server after the preset number of retries, the email is bounced back
to the sender as a permanent failure.
Server
Busy:
If the recipient server is busy, the email will be placed in the
retry queue and will be retried after some time.
Greylisting:
Some recipient server, when receiving emails from specific domains
for the first time, they greylist the emails by throwing temporary errors.
Mostly these emails will be delivered in subsequent retries.
Too
Many Emails/ Email Policies:
Some servers greylist the emails, in case they notice a sudden
surge in the number of emails received from a specific domain or specific IP
Address. This temporary rejection is based on the email policy of the recipient
server.
Other
reasons:
Some recipient servers give 4xx errors when the recipient mailbox
is full or based on the Anti-spam settings of the domain/ server etc. In case
of Zoho Mail, the no MX records found is treated as a temporary error and the
email is placed in the Retry queue.
Finger
and top
What
Does Finger Mean?
Finger is a networking tool and one of the earliest computer
networking programs that enabled a user to view another user’s basic
information when using the same computer system or logged on in the same
network. The program can determine user identity though an email address and
determine whether that user is currently logged in, as well as the status of
their log sessions.
It was originally created by Les Earnest in 1971 and later became
a standard part of BSD UNIX, and was commonly used by Windows users. This was
later interfaced by David Zimmerman with the Name program to become the
Name/Finger Protocol in 1977.
Finger was duly named for the act of pointing, as it points to a
person as well as to different information regarding that user. When invoked,
Finger displays information including the user’s real name, office location,
phone number, and even their last login time, although the information
displayed can be modified depending on the data maintained by the user in the
computer system.
To be able to Finger another web user, the program must be
installed in the user’s computer or access a Finger gateway and type the user’s
email address. The server at the other end must be able to handle Finger
requests too.
USENET
What
Does USENET Mean?
Usenet
definition. Usenet is one of the oldest computer
network communication systems.
Usenet is a worldwide system for Internet discussion that consists
of a set of newsgroups that are organized by subject. Users post articles or
messages to these newsgroups. The articles are then broadcast to other computer
systems, most of which now connect via the Internet. Usenet was conceived in
1979, making it one of the oldest network communications systems still in use
today. It is also the predecessor of many of the forums online today.
Usenet got its name from Unix-to-Unix Copy (UUCP), a protocol suite
for sending data, usually over a dial-up network. Initially, this was the
dominant mode of transmission for Usenet, but it has since come to rely on the
Internet.
Some newsgroups are moderated, which means that posts are sent to
a moderator for approval before being distributed to the group. Usenet users
exchange articles by tagging them with universally recognized labels. Many
Internet service providers and Internet sites provide news servers, which allow
their users to handle Usenet articles. Although Usenet is still used, it has
become less important in the face of online forums, blogs and mailing lists.
Examples
include Usenet Storm, Newshosting, and Astraweb, among many others. Some
services offer web-based tools to access and contribute to newsgroups, but you
can also use a newsreader, such as Newsbin, Agent, and Pan.
News groups
What is
a newsgroup?
A newsgroup is a discussion about a particular subject consisting
of notes written to a central internet site and redistributed through
Usenet, a worldwide network of news discussion groups. Usenet uses the Network
News Transfer Protocol, or NNTP.
Usenet was created in the 1980s as a way for researchers and
academics to share information and ideas. Although newsgroups are not as
popular as they used to be, they still have a dedicated community of users who
enjoy connecting over shared interests. Usenet remains a valuable resource for
researchers and academics.
How
does a Usenet newsgroup function?
The newsgroup functions as a distributed system, meaning that the
messages, or articles, are stored on multiple servers around the
world rather than on a central server.
From there, newsgroups are organized into subject hierarchies,
with the first few letters of the newsgroup name showing the major subject category
and subcategories represented by a subtopic name. Many subjects have
multiple levels of subtopics. Some major subject categories include news, rec
(recreation), soc (society), sci (science), comp (computers) and so forth --
there are many more.
Users can post to existing newsgroups and respond to previous
posts. They can also create their own new newsgroups, but it requires some
technical knowledge and permission from the server's administrator.
How do
you access a newsgroup?
To access a newsgroup, a user typically needs a Usenet client,
which is a program that allows users to connect to a Usenet server and read and
post messages. Some popular Usenet clients include Thunderbird and Unison.
How do
you post a message in a newsgroup?
When a user posts a message to a Usenet newsgroup, the message is
sent to the server to which the user is connected. The server then forwards the
message to other servers in the Usenet network. This process is known as
propagation.
As the message propagates, it is stored on servers around the
world, making it available to users who wish to read it. The messages in a
Usenet newsgroup are typically organized in a threaded format, meaning that
they are grouped together based on the subject of the message.
When a user posts a message, it becomes the "root" of
the thread. Other users can then reply to the message, creating a
"branch" of the thread. This allows for a more organized and
easy-to-follow discussion.
What
are some of the challenges of using a newsgroup?
Some common issues concerning the use of Usenet newsgroups
include spam, viruses and inappropriate content. Spam messages,
or unsolicited commercial messages, can flood a newsgroup and make it difficult
for users to find relevant information.
Viruses can also be spread through Usenet messages, potentially
causing harm to a user's computer. In addition, some users might post
inappropriate or offensive content, making the newsgroup a hostile or unsafe
environment for other users.
Usenet servers have implemented some measures such as filtering or
moderated groups to help mitigate these issues, but it remains a concern for
many users.
Are
newsgroups moderated?
Some newsgroups are moderated by a designated person who decides
which postings to allow or to remove. Most newsgroups are unmoderated, however;
newcomers to newsgroups are requested to learn basic Usenet
"netiquette" and to get familiar with a newsgroup before posting to
it.
The rules can be found when you enter Usenet through your browser
or an online service, but some general considerations are as follows:
First, when taking part in newsgroups, remember that other people
are reading your messages and might react to what you post. Be respectful of
others and familiarize yourself with the rules and guidelines for posting before
participating.
It's also important to remember that newsgroups are public forums,
and any information you post will be visible to everyone. It's best to avoid
posting sensitive or personal information. Make sure you double-check the
accuracy of any facts or figures you post, as incorrect information can lead to
confusion and negative reactions.
Finally, take the time to read other people's posts before
replying or starting a new thread. This will help you avoid repeating
information that has already been discussed and ensures everyone can take part
in the conversation with fresh ideas.
Internet programming WWW
Introduction
:
The Internet is a global network of interconnected computer
systems that enables communication and the sharing of information across the
world. The Internet has revolutionized the way people communicate, learn, and
conduct business.
Web programming refers to the development of web applications and
websites that are accessed over the Internet. Web programming involves creating
web pages, web applications, and other online content that can be displayed in
a web browser.
Web programming is accomplished using a variety of programming
languages, including HTML, CSS, JavaScript, PHP, Python, Ruby, and Java. Each
of these languages has its strengths and weaknesses, and the choice of language
depends on the needs of the project.
Web programming involves creating dynamic websites that are
interactive and user-friendly. This includes the use of databases, server-side
scripting, and client-side scripting to create applications that can process
data, display content, and interact with users.
The Internet is a vast network of computers, and servers, which
communicate with each other. The internet connects the whole wide world
together. The Internet is a vast network that connects billions of computers
and other electronic devices all around the world. You can get nearly any
information, communicate with anyone on the globe, and do a lot more with the
Internet. All of this is possible by connecting a computer to the Internet,
generally known as going online. When someone says a computer is online, they
are simply referring to the fact that it is linked to the Internet. How does it
actually work at a very low level?
Client-side:
First, when we type a URL like www.google.com,
the browser converts it into a file containing:
GET /HTTP/1.1 (where GET means we are requesting some data from
the server and HTTP refers to a protocol that we are using, 1.1 refers to the
version of the HTTP request)
Host: www.google.com
And some other information
Now this file is converted to binary code by the browser and it is
sent down the wires if we are connected through Ethernet and if we are using
WiFi, first it converts it to a radio signal which is decoded by a router in a
very low level. It is converted to binary and then sent to the servers.
This information or ‘binary codes’ go to the destination and
respond if it is received by the sender only because of the IP address.
One router will send the information to another and this keeps on
going until the binary codes reach the destination.
Server-side:
Now the server receives the binary code and
decodes it and sends the response in the following manner:
HTTP/1.1 200 ok (where 200 ok is the status)
Content-type:type/HTML
Body of
page
Now,
this is converted back to binary by the server and sent to the IP address that
is requesting it. Once the codes are received by the client, the browser again
decodes the information in the following way:
First, it checks the status
It starts reading the document from the HTML tag and constructs a
Tree-like structure.
The HTML tree is then converted to corresponding binary code and
rendered on the screen.
In the end, we see the website front-end.
Below is the tree structure of the HTML document:

The following diagram shows the whole process:

Uses of
Internet and Web programming :
The Internet and web programming have a wide
range of uses and applications. Here are some of the most common uses:
Communication: The
Internet has revolutionized communication, allowing people to connect with each
other through email, social media, video conferencing, and instant messaging.
Information
sharing: The Internet has made it possible to
access vast amounts of information quickly and easily. Websites like Wikipedia
and news sites provide up-to-date information on a wide range of topics.
E-commerce: The
Internet has enabled businesses to sell products and services online, creating
new opportunities for entrepreneurs and small businesses.
Education: The
Internet has opened up new opportunities for education, making it possible for
people to learn online through MOOCs, webinars, and other online courses.
Entertainment: The
Internet has transformed the way we consume entertainment, with streaming
services like Netflix and YouTube providing access to movies, TV shows, and
other content.
Web programming plays a crucial role in enabling many of these applications.
Web programming is used to create websites, online stores, web applications,
and other online services that are accessed through the Internet. Web
programming languages like HTML, CSS, JavaScript, PHP, and Python are used to
create these web-based applications.
Issues
in Internet and Web programming :
Some of the most significant issues in Internet and web
programming:
Security: Security
is a critical concern in web programming, as hackers can exploit
vulnerabilities in web applications to gain unauthorized access to sensitive
data or cause damage. Developers need to implement strong security measures to
protect against these threats.
Compatibility: The
Internet and web programming involve a wide range of devices, browsers, and
operating systems. Ensuring compatibility across all of these platforms can be
a significant challenge for developers.
Performance: Web
applications need to be responsive and perform well, even under heavy loads.
This requires careful optimization of code, server infrastructure, and other
resources.
Accessibility: Web
applications need to be accessible to people with disabilities, including those
who use assistive technologies like screen readers or voice recognition
software.
Privacy: As
web applications collect and process user data, privacy concerns have become
increasingly important. Developers need to implement strong privacy policies
and ensure that user data is protected.
Usability: Web
applications need to be easy to use and navigate, with intuitive interfaces
that provide a positive user experience.
Hypertext
What
Does Hypertext Mean?
Hypertext refers to a word, phrase or chunk of text that can be
linked to another document or text. Hypertext covers both textual hyperlinks
and graphical ones. The term was coined by Ted Nelson in the 1960s and is one
of the key concepts that makes the Internet work. Without hypertext, following
a link on a topic to a related article on that topic – one of the primary means
of navigating the Web – would be impossible.
The concept of hypertext was central to the creation of the World
Wide Web. Through the use of textual links, Web pages written in HyperText
Markup Language (HTML) can be linked and cross-referenced throughout the Web.
Ted Nelson actually had a far grander vision for hypertext than Tim
Berners-Lee’s World Wide Web, but his project, Xanadu is still under
development many decades later.
Nelson also coined the term hypermedia to refer to graphics,
sounds and animations that could be similarly interlinked.
Hypertext
Take a dictionary and observe how its content is linked together.
How do you search for the meaning of a word?
How can you find another word synonymous with that word?
The dictionary is a paper example of a hypertext system. So are
encyclopedias, product catalogues, user help books, technical documentation and
many other kinds of books. Information is obtained by searching through some
kind of index - the dictionary is arranged in alphabetical order, and each word
is its own index. Readers are then pointed to the page of any other related
information. They can read the information they are interested in without
having to read the document sequentially from beginning to end.
Hypertext systems allow for non-sequential, or non-linear,
reading. This is the underlying idea of a hypertext system. The result is a
multidimensional document that can be read by following different paths through
it. In this section we will look into the application of hypertext in computer
systems, mainly the World Wide Web hypertext system.
The main use of hypertext is in information retrieval
applications. The ease of linking different pieces (fragments) of information
is the important aspect of hypertext information retrieval. The information can
be of various media: it may be fragments of textual documents, structured data
from databases, or list of terms and their definitions. Any of these, or a
mixture thereof, can make up the contents of a hypertext document.
Therefore,
in a hypertext system it is possible to:
Link with a term that represents aspects of the content of a
document connect two related documents relate a term to a fragment containing
its definition and use link two related terms
Such a hypertext system can store a large collection of textual
and multimedia documents. Such a hypertext system gives the end-user access to
a large repository of knowledge for reading, browsing and retrieving. This is a
"database" of sorts, and is the reason why such a hypertext system is
called a digital library. The Web started as an extensively large digital
library. As it has grown in popularity, it has offered the possibility of
interactive applications and commerce on the Internet, making it much more than
a digital library.
To do:
Read about networked hypertext and hypermedia in your textbooks.
A hypertext document contains links referring to other parts of
the document, or even to whole other documents. A hypertext document does not
have to be read serially; the fragments of information can be accessed directly
via the links contained in the document.
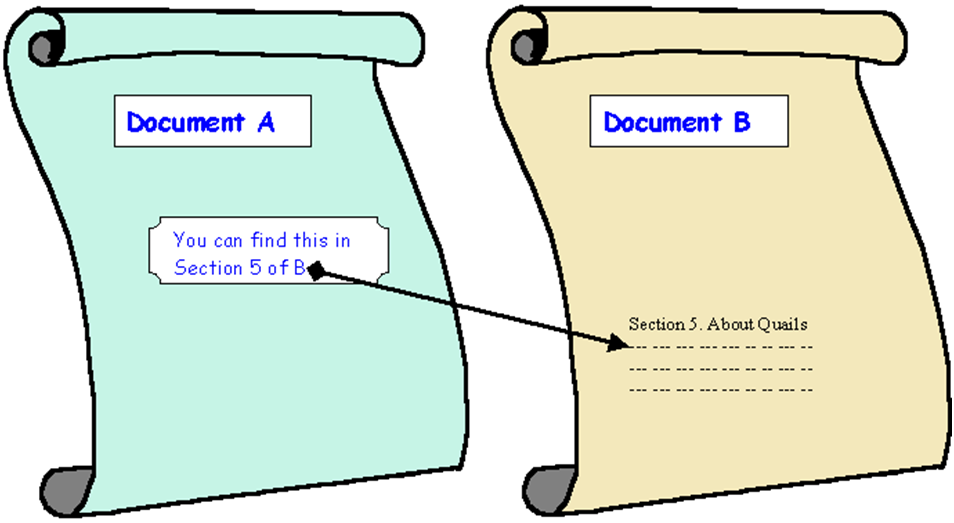
A computerised hypertext system implements this idea by including
anchors and links in documents, which are usually represented by files. An
anchor is a fragment of information which links to another document or portion
thereof. It is the visual representation of a link. A link is the actual
reference (or "pointer") to the other document. For example, in the
diagram below, the fragment of Document A containing 'You can find this in
Section 5 of B' is an anchor from which there is a link to the relevant section
in Document B.
Take care not to confuse anchor or link. A link is a pointer to
another piece of information within the same document or in another document;
often you cannot see how that link is implemented (it may be a hidden URL or
some other programmed mechanism). An anchor is a fragment of information which
the user interacts with in order to access the link. For instance, in a Web
Browser the phrase "Click here to return to the previous page" is the
anchor which the user interacts with — it contains the link to the previous
page.
A
hyperlink must have unambiguous reference to the document:
this is usually information on the document's location (where in some file
space or network it is) and the mechanism to access it (called the
communication protocol). In Unit 2 you will meet HTML anchors and how the
referenced documents are identified and located with URLs.
A hypertext document allow links to portions of the document
occurring before the link's anchor. This allows the reader to loop to portions
of the document that they have already seen.
The table of contents in a book is a collection of anchors with
explicit links to the internal parts of the book. Its bibliography is another
collection of links but it refers to external information. To refer to the
internal parts of the book is simple: the reader merely turns to the
appropriate page, usually identified by page number. However, referring to the
external information given in a bibliography requires a more complicated effort
of searching.
In computer-based hypertext documents, the mechanism to follow a
link (the jump) is automatic. Jumping to an external link (another document) is
as easy as jumping to an internal link within the same document. As long as the
link is sufficiently specified with the name and the exact location of the
linked document, the user can directly access the linked document with a simple
click on the anchor.
A series of successive jumps constructs a chained path through a
series of documents. There is no limit as to the number of jumps, therefore the
size of the chain is not constrained.
There may be more than one link in a page and the reader is free
to choose any of these links to follow. The path a reader takes will then be
different from the path of another reader. Each sequence of jumps forms a
different path to fragments of the overall information in the hypertext
document. Generally, there is no rigid order to read the information in.
There are two different but complementary purposes of chaining
documents via links:
Focusing:
At each jump along the path, the user can narrow the scope of the search until
the fragment containing the topic of their interest is reached.
Broadening:
Multiple outgoing links from a document allow the user to broaden their search.
This is useful when the user does not have a precise idea of what is being
searched for, or wishes to conduct a broad search in a certain domain.
Travelling through hypertext documents usually poses no technical
difficulty. However, the reader might experience practical difficulties in
retrieving a particular piece of information from a document with numerous
alternative links.
Just as the reader is free to choose which links and jumps a path
through a hypertext document is to follow, it is possible for a user to return
to a point previously visited. In other words, loops may exist. A path may even
return to the original (home) document. Hence, the structure does not
necessarily follow a linear pattern; instead, the documents are connected
together in a graph / mesh defined by the links.
This critical property shifts the burden of devising suitable
exploration paths from the designer of a hypertext document to the user. This
changes the way information is stored and retrieved. Instead of searching
directly for information, hypertext allows browsing for information. However,
the mesh of information creates difficulty in navigating through the hypertext
document.
One of the original purposes for hypertext was the storage and
management of textual documents. As computer and telecommunications technology
has improved, the capabilities of hypertext systems have been extended to
include any digitised media, such as sound and images.
This means that music and videos can be accessed via hyperlinks.
This addition of multimedia to hypertext is known as Hypermedia. A combination
of text, graphics, video or sound can now easily be interlinked in hypermedia
document to offer a rich, often interactive, environment.
HTTP
HTTP
stands for HyperText Transfer Protocol.
It is a protocol used to access the data on the World Wide Web
(www).
The HTTP protocol can be used to transfer the data in the form of
plain text, hypertext, audio, video, and so on.
This protocol is known as HyperText Transfer Protocol because of
its efficiency that allows us to use in a hypertext environment where there are
rapid jumps from one document to another document.
HTTP is similar to the FTP as it also transfers the files from one
host to another host. But, HTTP is simpler than FTP as HTTP uses only one
connection, i.e., no control connection to transfer the files.
HTTP is used to carry the data in the form of MIME-like format.
HTTP is similar to SMTP as the data is transferred between client
and server. The HTTP differs from the SMTP in the way the messages are sent
from the client to the server and from server to the client. SMTP messages are
stored and forwarded while HTTP messages are delivered immediately.
Features
of HTTP:
Connectionless
protocol: HTTP is a connectionless protocol. HTTP
client initiates a request and waits for a response from the server. When the
server receives the request, the server processes the request and sends back
the response to the HTTP client after which the client disconnects the
connection. The connection between client and server exist only during the
current request and response time only.
Media
independent: HTTP protocol is a media independent as
data can be sent as long as both the client and server know how to handle the
data content. It is required for both the client and server to specify the
content type in MIME-type header.
Stateless: HTTP
is a stateless protocol as both the client and server know each other only
during the current request. Due to this nature of the protocol, both the client
and server do not retain the information between various requests of the web
pages.
HTTP
Transactions

The above figure shows the HTTP transaction between client and
server. The client initiates a transaction by sending a request message to the
server. The server replies to the request message by sending a response
message.
Messages


Request Message: The request message is sent by the client that consists of a request line, headers, and sometimes a body.

Response Message: The response message is sent by the server to the client that consists of a status line, headers, and sometimes a body.

URL
What is
a URL with example?
URL is an acronym for Uniform Resource Locator and is a
reference (an address) to a resource on the Internet. A URL has two main
components: Protocol identifier: For the URL http://example.com , the protocol
identifier is http . Resource name: For the URL http://example.com , the resource
name is example.com
URL stands for Uniform Resource Locator. A URL is
nothing more than the address of a given unique resource on the Web. In theory,
each valid URL points to a unique resource. Such resources can be an HTML page,
a CSS document, an image, etc. In practice, there are some exceptions, the most
common being a URL pointing to a resource that no longer exists or that has
moved. As the resource represented by the URL and the URL itself are handled by
the Web server, it is up to the owner of the web server to carefully manage
that resource and its associated URL.
Uniform
Resource Locator (URL)
A client that wants to access the document in an internet needs an
address and to facilitate the access of documents, the HTTP uses the concept of
Uniform Resource Locator (URL).
The Uniform Resource Locator (URL) is a standard way of specifying
any kind of information on the internet.
The URL defines four parts: method, host computer, port, and path.

Method: The method is the protocol used to retrieve the
document from a server. For example, HTTP.
Host: The
host is the computer where the information is stored, and the computer is given
an alias name. Web pages are mainly stored in the computers and the computers
are given an alias name that begins with the characters "www". This
field is not mandatory.
Port: The
URL can also contain the port number of the server, but it's an optional field.
If the port number is included, then it must come between the host and path and
it should be separated from the host by a colon.
Path: Path
is the pathname of the file where the information is stored. The path itself
contain slashes that separate the directories from the subdirectories and
files.
HTML Programming
HTML stands for HyperText Markup Language. It is used to
design web pages using a markup language. HTML is a combination of Hypertext
and Markup language. Hypertext defines the link between web pages. A markup
language is used to define the text document within the tag which defines the
structure of web pages. This language is used to annotate (make notes for the
computer) text so that a machine can understand it and manipulate text
accordingly. Most markup languages (e.g. HTML) are human-readable. The language
uses tags to define what manipulation has to be done on the text.

HTML is a markup language used by the browser to manipulate text,
images, and other content, in order to display it in the required format. HTML
was created by Tim Berners-Lee in 1991. The first-ever version of HTML was HTML
1.0, but the first standard version was HTML 2.0, published in 1995.
Elements and Tags: HTML uses predefined tags and elements which tell the browser how to properly display the content. Remember to include closing tags. If omitted, the browser applies the effect of the opening tag until the end of the page.
HTML page structure: The basic structure of an HTML page is
laid out below. It contains the essential building-block elements (i.e. doctype
declaration, HTML, head, title, and body elements) upon which all web pages are
created.
HTML
Page Structure
<!DOCTYPE html> Version
of HTML
<html> HTML
Root Element
<head> Used
to contain page HTML metadata
<title> Page Title </title> Title of HTML page
</head>
<body> Hold
content of Html
<h2> Heading Content </h2> HTML heading tag
<p> Paragraph Content </p> HTML paragraph tag
</body>
</html>
<!DOCTYPE
html>: This is the document type declaration
(not technically a tag). It declares a document as being an HTML document. The
doctype declaration is not case-sensitive.
<html>: This
is called the HTML root element. All other elements are contained within it.
<head>: The
head tag contains the “behind the scenes” elements for a webpage. Elements
within the head aren’t visible on the front-end of a webpage. HTML elements
used inside the <head> element include:
<style>-This html tag allows us to insert styling into our
webpages and make them appealing to look at with the help of CSS.
<title>-The title is what is displayed on the top of your browser
when you visit a website and contains the title of the webpage that you are
viewing.
<base>-It specifies the base URL for all relative URL’s in a
document.
<noscript>– Defines a section of HTML that is inserted when
the scripting has been turned off in the users browser.
<script>-This tag is used to add functionality in the
website with the help of
JavaScript.
<meta>-This tag encloses the meta data of the website that
must be loaded every time the website is visited. For eg:- the metadata charset
allows you to use the standard UTF-8 encoding in your website. This in turn
allows the users to view your webpage in the language of their choice. It is a
self closing tag.
<link>– The ‘link’ tag is used to tie together HTML, CSS,
and JavaScript. It is self closing.
<body>: The
body tag is used to enclose all the visible content of a webpage. In other
words, the body content is what the browser will show on the front-end.
An HTML document can be created using any text editor. Save the
text file using .html or .htm. Once saved as an HTML document,
the file can be opened as a webpage in the browser.
Note: Basic/built-in
text editors are Notepad (Windows) and TextEdit (Macs). Basic text editors are
entirely sufficient for when you’re just getting started. As you progress,
there are many feature-rich text editors available which allow for greater
function and flexibility.
Example:
This example illustrates the basic structure of HTML code.
HTML
|
<!DOCTYPE html> <html> <head> <meta
charset="UTF-8"> <meta
name="viewport" content="width=device-width,
initial-scale=1.0"> <!--The above meta
characteristics make a website compatible with different devices. --> <title>Demo
Web Page</title> </head> <body> <h1>Gcmc
Ballari</h1> <p>A
computer science Vocational Lab</p> </body> </html> |
Features
of HTML:
It is easy to learn and easy to use.
It is platform-independent.
Images, videos, and audio can be added to a web page.
Hypertext can be added to the text.
It is a markup language.
Why
learn HTML?
It is a simple markup language. Its implementation is easy.
It is used to create a website.
Helps in developing fundamentals about web programming.
Boost professional career.
Advantages:
HTML is used to build websites.
It is supported by all browsers.
It can be integrated with other languages like CSS, JavaScript,
etc.
Disadvantages:
HTML can only create static web pages. For dynamic web pages,
other languages have to be used.
A large amount of code has to be written to create a simple web
page.
The security feature is not good.
No comments:
Post a Comment