UNIT5: THE TRANSPORT LAYER AND
APPLICATION LAYER
Transport Layer
The transport layer is a 4th layer
from the top.
The main role of the transport layer is
to provide the communication services directly to the application processes
running on different hosts.
The transport layer provides a logical
communication between application processes running on different hosts. Although
the application processes on different hosts are not physically connected,
application processes use the logical communication provided by the transport
layer to send the messages to each other.
The transport layer protocols are
implemented in the end systems but not in the network routers.
A computer network provides more than
one protocol to the network applications. For example, TCP and UDP are two
transport layer protocols that provide a different set of services to the
network layer.
All transport layer protocols provide
multiplexing/demultiplexing service. It also provides other services such as
reliable data transfer, bandwidth guarantees, and delay guarantees.
Each of the applications in the application layer has the ability to send a message by using TCP or UDP. The application communicates by using either of these two protocols. Both TCP and UDP will then communicate with the internet protocol in the internet layer. The applications can read and write to the transport layer.
Therefore, we can say
that communication is a two-way process.

Services provided by the Transport Layer
The services provided by the transport
layer are similar to those of the data link layer. The data link layer provides
the services within a single network while the transport layer provides the
services across an internetwork made up of many networks. The data link layer
controls the physical layer while the transport layer controls all the lower
layers.
The services provided by the transport
layer protocols can be divided into five categories:
End-to-end delivery
Addressing
Reliable delivery
Flow control
Multiplexing

End-to-end delivery:
The transport layer transmits the entire
message to the destination. Therefore, it ensures the end-to-end delivery of an
entire message from a source to the destination.
Reliable delivery:
The transport layer provides reliability
services by retransmitting the lost and damaged packets.
The reliable delivery has four aspects:
Error control
Sequence control
Loss control
Duplication control

Error Control
The primary role of reliability is Error
Control. In reality, no transmission will be 100 percent error-free delivery.
Therefore, transport layer protocols are designed to provide error-free
transmission.
The data link layer also provides the
error handling mechanism, but it ensures only node-to-node error-free delivery.
However, node-to-node reliability does not ensure the end-to-end reliability.
The data link layer checks for the error
between each network. If an error is introduced inside one of the routers, then
this error will not be caught by the data link layer. It only detects those
errors that have been introduced between the beginning and end of the link.
Therefore, the transport layer performs the checking for the errors end-to-end
to ensure that the packet has arrived correctly.
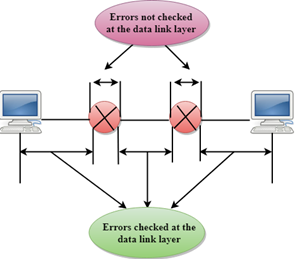
Sequence Control
The second aspect of the reliability is
sequence control which is implemented at the transport layer.
On the sending end, the transport layer
is responsible for ensuring that the packets received from the upper layers can
be used by the lower layers. On the receiving end, it ensures that the various
segments of a transmission can be correctly reassembled.
Loss Control
Loss Control is a third aspect of
reliability. The transport layer ensures that all the fragments of a
transmission arrive at the destination, not some of them. On the sending end,
all the fragments of transmission are given sequence numbers by a transport
layer. These sequence numbers allow the receiver?s transport layer to identify
the missing segment.
Duplication Control
Duplication Control is the fourth aspect
of reliability. The transport layer guarantees that no duplicate data arrive at
the destination. Sequence numbers are used to identify the lost packets;
similarly, it allows the receiver to identify and discard duplicate segments.
Flow Control
Flow control is used to prevent the
sender from overwhelming the receiver. If the receiver is overloaded with too
much data, then the receiver discards the packets and asking for the
retransmission of packets. This increases network congestion and thus, reducing
the system performance. The transport layer is responsible for flow control. It
uses the sliding window protocol that makes the data transmission more
efficient as well as it controls the flow of data so that the receiver does not
become overwhelmed. Sliding window protocol is byte oriented rather than frame
oriented.
Multiplexing
The transport layer uses the
multiplexing to improve transmission efficiency.
Multiplexing can occur in two ways:
Upward multiplexing: Upward
multiplexing means multiple transport layer connections use the same network
connection. To make more cost-effective, the transport layer sends several
transmissions bound for the same destination along the same path; this is
achieved through upward multiplexing.

Downward multiplexing: Downward multiplexing means one transport layer connection uses the multiple network connections. Downward multiplexing allows the transport layer to split a connection among several paths to improve the throughput. This type of multiplexing is used when networks have a low or slow capacity.

Addressing
According to the layered model, the
transport layer interacts with the functions of the session layer. Many
protocols combine session, presentation, and application layer protocols into a
single layer known as the application layer. In these cases, delivery to the
session layer means the delivery to the application layer. Data generated by an
application on one machine must be transmitted to the correct application on another
machine. In this case, addressing is provided by the transport layer.
The transport layer provides the user
address which is specified as a station or port. The port variable represents a
particular TS user of a specified station known as a Transport Service access
point (TSAP). Each station has only one transport entity.
The transport layer protocols need to
know which upper-layer protocols are communicating.
|
Transport Layer protocols The transport layer is represented by
two protocols: TCP and UDP. The IP protocol in the network layer
delivers a datagram from a source host to the destination host. Nowadays, the operating system
supports multiuser and multiprocessing environments, an executing program is
called a process. When a host sends a message to other host means that source
process is sending a process to a destination process. The transport layer
protocols define some connections to individual ports known as protocol
ports. An IP protocol is a host-to-host
protocol used to deliver a packet from source host to the destination host
while transport layer protocols are port-to-port protocols that work on the
top of the IP protocols to deliver the packet from the originating port to
the IP services, and from IP services to the destination port. Each port is defined by a positive
integer address, and it is of 16 bits. |
 UDP UDP stands for User Datagram
Protocol. UDP is a simple protocol and it provides
nonsequenced transport functionality. UDP is a connectionless protocol. This type of protocol is used when
reliability and security are less important than speed and size. UDP is an end-to-end transport level
protocol that adds transport-level addresses, checksum error control, and
length information to the data from the upper layer. The packet produced by the UDP protocol
is known as a user datagram. User Datagram Format The user datagram has a 16-byte header
which is shown below:
 Where, Source port address: It defines the
address of the application process that has delivered a message. The source
port address is of 16 bits address. Destination port address: It
defines the address of the application process that will receive the message.
The destination port address is of a 16-bit address. Total length: It defines the total
length of the user datagram in bytes. It is a 16-bit field. Checksum: The checksum is a 16-bit
field which is used in error detection. Disadvantages of UDP protocol UDP provides basic functions needed for
the end-to-end delivery of a transmission. It does not provide any sequencing or
reordering functions and does not specify the damaged packet when reporting an
error. UDP can discover that an error has
occurred, but it does not specify which packet has been lost as it does not
contain an ID or sequencing number of a particular data segment. TCP TCP stands for Transmission Control
Protocol. It provides full transport layer
services to applications. It is a connection-oriented protocol
means the connection established between both the ends of the transmission. For
creating the connection, TCP generates a virtual circuit between sender and
receiver for the duration of a transmission. Features Of TCP protocol Stream data transfer: TCP protocol
transfers the data in the form of contiguous stream of bytes. TCP group the
bytes in the form of TCP segments and then passed it to the IP layer for
transmission to the destination. TCP itself segments the data and forward to
the IP. Reliability: TCP assigns a sequence
number to each byte transmitted and expects a positive acknowledgement from the
receiving TCP. If ACK is not received within a timeout interval, then the data
is retransmitted to the destination. Flow Control: When receiving TCP
sends an acknowledgement back to the sender indicating the number the bytes it
can receive without overflowing its internal buffer. The number of bytes is
sent in ACK in the form of the highest sequence number that it can receive
without any problem. This mechanism is also referred to as a window mechanism. Multiplexing: Multiplexing is a
process of accepting the data from different applications and forwarding to the
different applications on different computers. At the receiving end, the data
is forwarded to the correct application. This process is known as
demultiplexing. TCP transmits the packet to the correct application by using
the logical channels known as ports. Logical Connections: The
combination of sockets, sequence numbers, and window sizes, is called a logical
connection. Each connection is identified by the pair of sockets used by sending
and receiving processes. Full Duplex: TCP provides Full
Duplex service, i.e., the data flow in both the directions at the same time. To
achieve Full Duplex service, each TCP should have sending and receiving buffers
so that the segments can flow in both the directions. TCP is a
connection-oriented protocol. Suppose the process A wants to send and receive
the data from process B. The following steps occur: Establish a connection between two TCPs. Data is exchanged in both the
directions. The Connection is terminated. TCP Segment Format
 Where, Source port address: It is used to
define the address of the application program in a source computer. It is a
16-bit field. Destination port address: It is
used to define the address of the application program in a destination
computer. It is a 16-bit field. Sequence number: A stream of data
is divided into two or more TCP segments. The 32-bit sequence number field
represents the position of the data in an original data stream. Acknowledgement number: A 32-field
acknowledgement number acknowledge the data from other communicating devices.
If ACK field is set to 1, then it specifies the sequence number that the
receiver is expecting to receive. Header Length (HLEN): It specifies
the size of the TCP header in 32-bit words. The minimum size of the header is 5
words, and the maximum size of the header is 15 words. Therefore, the maximum
size of the TCP header is 60 bytes, and the minimum size of the TCP header is
20 bytes. Reserved: It is a six-bit field
which is reserved for future use. Control bits: Each bit of a control
field functions individually and independently. A control bit defines the use
of a segment or serves as a validity check for other fields. There are total six types of flags in
control field: URG: The URG field indicates that
the data in a segment is urgent. ACK: When ACK field is set, then it
validates the acknowledgement number. PSH: The PSH field is used to
inform the sender that higher throughput is needed so if possible, data must be
pushed with higher throughput. RST: The reset bit is used to reset
the TCP connection when there is any confusion occurs in the sequence numbers. SYN: The SYN field is used to
synchronize the sequence numbers in three types of segments: connection
request, connection confirmation ( with the ACK bit set ), and confirmation
acknowledgement. FIN: The FIN field is used to
inform the receiving TCP module that the sender has finished sending data. It
is used in connection termination in three types of segments: termination
request, termination confirmation, and acknowledgement of termination
confirmation. Window Size: The window is a 16-bit
field that defines the size of the window. Checksum: The checksum is a 16-bit
field used in error detection. Urgent pointer: If URG flag is set
to 1, then this 16-bit field is an offset from the sequence number indicating
that it is a last urgent data byte. Options and padding: It defines the
optional fields that convey the additional information to the receiver. Differences b/w TCP & UDP
|
DNS: Overview
When DNS was not into
existence, one had to download a Host file containing host names and
their corresponding IP address. But with increase in number of hosts of
internet, the size of host file also increased. This resulted in increased
traffic on downloading this file. To solve this problem the DNS system was introduced.
Domain Name System helps to resolve
the host name to an address. It uses a hierarchical naming scheme and
distributed database of IP addresses and associated names
IP Address
IP address is a unique logical address
assigned to a machine over the network. An IP address exhibits the following
properties:
· IP
address is the unique address assigned to each host present on Internet.
· IP
address is 32 bits (4 bytes) long.
· IP
address consists of two components: network component and host
component.
· Each
of the 4 bytes is represented by a number from 0 to 255, separated with dots.
For example 137.170.4.124
IP address is 32-bit number while on the
other hand domain names are easy to remember names. For example, when we enter
an email address we always enter a symbolic string such as webmaster@ blogspot.com
Uniform Resource Locator (URL)
Uniform Resource Locator (URL) refers
to a web address which uniquely identifies a document over the internet.
This document can be a web page, image,
audio, video or anything else present on the web.
For example, www.blogspot.com
/internet_technology/index.html is an URL to the index.html which is
stored on blogspot.com web server under internet_technology
directory.
URL Types
There are two forms of URL as listed
below:
· Absolute
URL
· Relative
URL
Absolute URL
Absolute URL is a complete address of a
resource on the web. This completed address comprises of protocol used, server
name, path name and file name.
For example http:// www.blogspot.com /
internet_technology /index.htm. where:
· http is
the protocol.
· www.blogspot.com is
the server name.
· index.htm is
the file name.
The protocol part tells the web browser
how to handle the file. Similarly we have some other protocols also that can be
used to create URL are:
· FTP
· https
· Gopher
· mailto
· news
Relative URL
Relative URL is a partial address of a
webpage. Unlike absolute URL, the protocol and server part are omitted from
relative URL.
Relative URLs are used for internal
links i.e. to create links to file that are part of same website as the
WebPages on which you are placing the link.
For example, to link an image on
tutorialspoint.com/internet_technology/internet_referemce_models, we can use
the relative URL which can take the form like /internet_technologies/internet-osi_model.jpg.
Difference between Absolute and Relative
URL
|
Absolute URL |
Relative URL |
|
Used to link web pages on different
websites |
Used to link web pages within the same
website. |
|
Difficult to manage. |
Easy to Manage |
|
Changes when the server name or
directory name changes |
Remains same even of we change the
server name or directory name. |
|
Take time to access |
Comparatively faster to access. |
Domain Name System Architecture
The Domain name system comprises
of Domain Names, Domain Name Space, Name Server that have been
described below:
Domain Names
Domain Name is a symbolic string
associated with an IP address. There are several domain names available; some
of them are generic such as com, edu, gov, net etc, while some
country level domain names such as au, in, za, us etc.
The following table shows the Generic Top-Level
Domain names:
|
|
|
|
Domain Name |
Meaning |
|
Com |
Commercial business |
|
Edu |
Education |
|
Gov |
U.S. government agency |
|
Int |
International entity |
|
Mil |
U.S. military |
|
Net |
Networking organization |
|
Org |
Non profit organization |
The following table shows the Country top-level domain names:
|
|
|
|
Domain Name |
Meaning |
|
au |
Australia |
|
in |
India |
|
cl |
Chile |
|
fr |
France |
|
us |
United States |
|
za |
South Africa |
|
uk |
United Kingdom |
|
jp |
Japan |
|
es |
Spain |
|
de |
Germany |
|
ca |
Canada |
|
ee |
Estonia |
|
hk |
Hong Kong |
Domain Name Space
The domain name space refers a hierarchy
in the internet naming structure. This hierarchy has multiple levels (from 0 to
127), with a root at the top. The following diagram shows the domain name space
hierarchy:

In the above diagram each subtree
represents a domain. Each domain can be partitioned into sub domains and these
can be further partitioned and so on.
Name Server
Name server contains the DNS database.
This database comprises of various names and their corresponding IP addresses.
Since it is not possible for a single server to maintain entire DNS database,
therefore, the information is distributed among many DNS servers.
· Hierarchy
of server is same as hierarchy of names.
· The
entire name space is divided into the zones
Zones
Zone is collection of nodes (sub
domains) under the main domain. The server maintains a database called zone
file for every zone.

If the domain is not further divided
into sub domains then domain and zone refers to the same thing.
The information about the nodes in the
sub domain is stored in the servers at the lower levels however; the original
server keeps reference to these lower levels of servers.
Types of Name Servers
Following are the three categories of
Name Servers that manages the entire Domain Name System:
· Root
Server
· Primary
Server
· Secondary
Server
Root Server
Root Server is the top level server
which consists of the entire DNS tree. It does not contain the information
about domains but delegates the authority to the other server
Primary Servers
Primary Server stores a file about its
zone. It has authority to create, maintain, and update the zone file.
Secondary Server
Secondary Server transfers complete
information about a zone from another server which may be primary or secondary
server. The secondary server does not have authority to create or update a zone
file.
DNS Working
DNS translates the domain name into IP
address automatically. Following steps will take you through the steps included
in domain resolution process:
· When
we type www.blogspot.com into the browser, it asks the local DNS
Server for its IP address.
Here the local DNS is at ISP end.
· When
the local DNS does not find the IP address of requested domain name, it
forwards the request to the root DNS server and again enquires about IP address
of it.
· The
root DNS server replies with delegation that I do not know the IP address
of www.blogspot.com but know the IP address of DNS Server.
· The
local DNS server then asks the com DNS Server the same question.
· The com DNS
Server replies the same that it does not know the IP address of www.blogspot.com but
knows the address of tutorialspoint.com.
· Then
the local DNS asks the tutorialspoint.com DNS server the same question.
· Then www.blogspot.com DNS
server replies with IP address of www.tutorialspoint.com.
· Now,
the local DNS sends the IP address of www.blogspot.com to the
computer that sends the request.
ELECTRONIC MAILING:
Introduction to Electronic Mail
Electronic Mail (e-mail) is one of
most widely used services of Internet. This service allows an Internet
user to send a message in formatted manner (mail) to the other
Internet user in any part of world. Message in mail not only contain text, but
it also contains images, audio and videos data. The person who is sending mail
is called sender and person who receives mail is called recipient.
It is just like postal mail service. Components of E-Mail System : The
basic components of an email system are : User Agent (UA), Message Transfer
Agent (MTA), Mail Box, and Spool file. These are explained as following below.
1. User
Agent (UA) : The UA is normally a program which is used to send and
receive mail. Sometimes, it is called as mail reader. It accepts variety of
commands for composing, receiving and replying to messages as well as for
manipulation of the mailboxes.
2. Message
Transfer Agent (MTA) : MTA is actually responsible for transfer of mail
from one system to another. To send a mail, a system must have client MTA and
system MTA. It transfer mail to mailboxes of recipients if they are connected
in the same machine. It delivers mail to peer MTA if destination mailbox is in
another machine. The delivery from one MTA to another MTA is done by Simple
Mail Transfer Protocol.

3. Mailbox : It is a file on local hard drive to collect mails. Delivered mails are present in this file. The user can read it delete it according to his/her requirement. To use e-mail system each user must have a mailbox . Access to mailbox is only to owner of mailbox.
4. Spool file
: This file contains mails that are to be sent. User agent appends
outgoing mails in this file using SMTP. MTA extracts pending mail from spool
file for their delivery. E-mail allows one name, an alias, to represent
several different e-mail addresses. It is known as mailing list, Whenever
user have to sent a message, system checks recipient’s name against alias
database. If mailing list is present for defined alias, separate messages, one
for each entry in the list, must be prepared and handed to MTA. If for defined
alias, there is no such mailing list is present, name itself becomes naming
address and a single message is delivered to mail transfer entity.
Services provided by E-mail system :
· Composition
– The composition refer to process that creates messages and answers. For
composition any kind of text editor can be used.
· Transfer
– Transfer means sending procedure of mail i.e. from the sender to
recipient.
· Reporting
– Reporting refers to confirmation for delivery of mail. It help user to
check whether their mail is delivered, lost or rejected.
· Displaying
– It refers to present mail in form that is understand by the user.
· Disposition
– This step concern with recipient that what will recipient do after
receiving mail i.e save mail, delete before reading or delete after reading.
World Wide Web (WWW)
The World Wide Web is
abbreviated as WWW and is commonly known as the web. The WWW was initiated by
CERN (European library for Nuclear Research) in 1989.
WWW can be defined as the collection of
different websites around the world, containing different information shared
via local servers(or computers).
History:
It is a project created, by Timothy Berner Lee in 1989, for researchers to work
together effectively at CERN. is an organization, named the World Wide Web
Consortium (W3C), which was developed for further development of the web. This
organization is directed by Tim Berner’s Lee, aka the father of the web.
System Architecture:
From the user’s point of view, the web consists of a vast, worldwide connection
of documents or web pages. Each page may contain links to other pages anywhere
in the world. The pages can be retrieved and viewed by using browsers of which
internet explorer, Netscape Navigator, Google Chrome, etc are the popular ones.
The browser fetches the page requested interprets the text and formatting
commands on it, and displays the page, properly formatted, on the screen.
The basic model of how the web works are
shown in the figure below. Here the browser is displaying a web page on the
client machine. When the user clicks on a line of text that is linked to a page
on the abd.com server, the browser follows the hyperlink by sending a message
to the abd.com server asking it for the page.

Here the browser displays a web page on
the client machine when the user clicks on a line of text that is linked to a
page on abd.com, the browser follows the hyperlink by sending a message to the
abd.com server asking for the page.
Working of WWW:
The World Wide Web is based on several different technologies: Web browsers,
Hypertext Markup Language (HTML) and Hypertext Transfer Protocol (HTTP).
A Web browser is used to access web pages. Web browsers can be defined as programs which display text, data, pictures, animation and video on the Internet.
Hyperlinked resources on the
World Wide Web can be accessed using software interfaces provided by Web
browsers. Initially, Web browsers were used only for surfing the Web but now
they have become more universal. Web browsers can be used for several tasks
including conducting searches, mailing, transferring files, and much more. Some
of the commonly used browsers are Internet Explorer, Opera Mini, and Google
Chrome.
Features of WWW:
· HyperText
Information System
· Cross-Platform
· Distributed
· Open
Standards and Open Source
· Uses
Web Browsers to provide a single interface for many services
· Dynamic,
Interactive and Evolving.
· “Web
2.0”
Components of the Web: There are 3 components of the
web:
1. Uniform Resource Locator (URL): serves
as a system for resources on the web.
2. HyperText
Transfer Protocol (HTTP): specifies communication of browser and server.
3. Hyper Text Markup Language (HTML): defines the structure, organisation and content of a webpage.
How world-wide-web (www) is different from the Internet ?
Before answering the question of how www is different from the Internet?
First, let’s understand what does
Internet means?
According to Wikipedia, the definition
of the Internet is:
The Internet (a portmanteau of the
interconnected network) is the global system of interconnected computer
networks that uses the Internet protocol suite (TCP/IP) to link devices
worldwide.
In simple terms, it is also known
as Networks of Networks which links all devices together globally.
Is anyone in charge of the
Internet?
Honestly, nobody is in charge of the
Internet. The Internet is a large distributed network there is no central
authority of controlling how the packets should be routed from the networks. It
makes sure everyone has end-to-end connectivity Just like a phone call.
Now, let’s talk about what is the world wide web is?
An information system on the Internet
which allows documents to be connected to other documents by hypertext links,
enabling the user to search for information by moving from one document to
another.
World Wide Web is one of the
services which is provided by the internet over HTTP (HyperText Transfer
Protocol). It uses URL(Uniform
Resource Locator) to locate file and HTML(Hypertext markup
language) to display the information which can be rendered by your
browser.
In analogy, we can consider the World
Wide Web as a movie theatre and the road as an internet.
Apart from world-wide-web, the Internet
supports other protocols like FTP(File Transfer Protocol), SMTP(Simple Mail Transfer Protocol), POP(Post
Office Protocol), etc.
Nowadays the rise in mobile computing
there is a steady decline in the usage of the World Wide Web. Most of the World
Wide Web services are provided as mobile app like Gmail, Spotify, YouTube, etc.
which are easily accessible to the users.
![]()
No comments:
Post a Comment